We teach AWS for the real world - not for certifications. Join more than 10,500 developers learning how to build real-world applications on AWS.
When does serverless stop being the answer?
|
AWS FOR THE REAL WORLD
⏱️
Reading time: 11 minutes
🎯
Main Learning: Most teams should stay serverless. EKS only pays off at real scale.
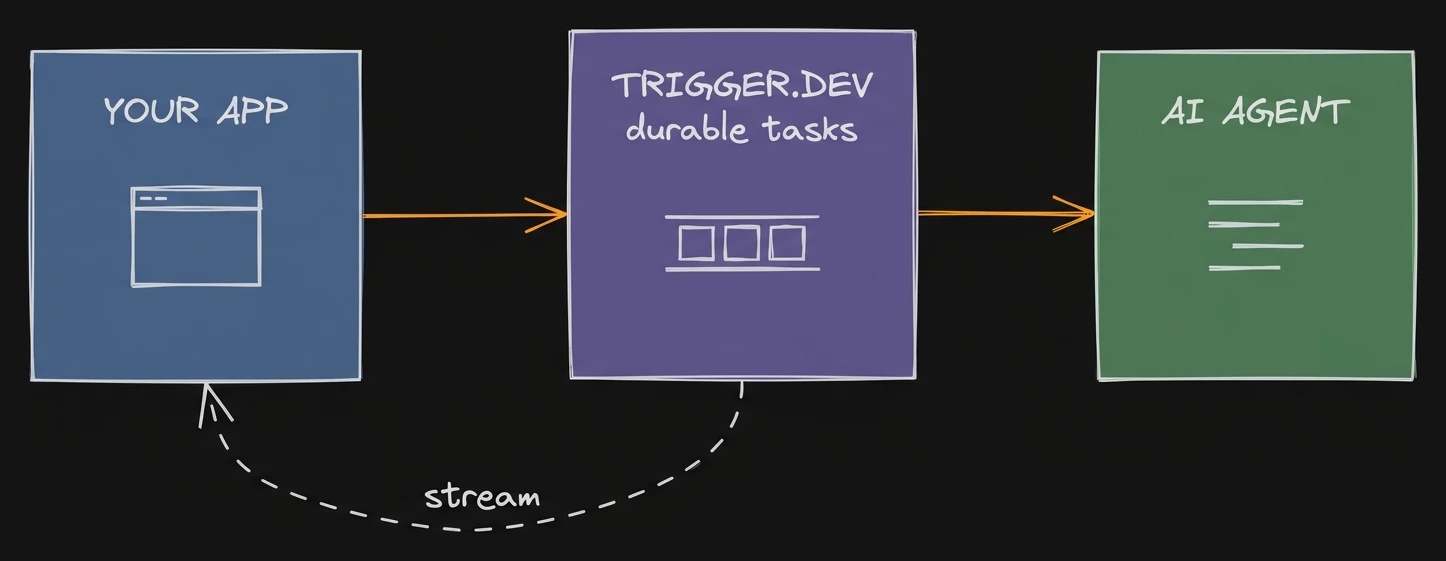
Hey Reader 👋🏽 And we meant it. Running k8s yourself is a second full-time job. Cluster upgrades, etcd backups, some networking plugin that falls over on a Tuesday and nobody can say why. This issue is sponsored by Trigger.dev.
That's a wrap for this one. Catch you in the next one! Sandro & Tobi |

AWS for the Real World
We teach AWS for the real world - not for certifications. Join more than 10,500 developers learning how to build real-world applications on AWS.
AWS FOR THE REAL WORLD ⏱️ Reading time: 12 minutes 🎯 Main Learning: Most of the complaints in the viral "leaving AWS" post are skill issues — but egress pricing is a fair hit. 📝 Blog Post Hey Reader 👋🏽Recently, a post with the title "I returned to AWS and was reminded why I left" hit 810 upvotes on Hacker News last week and went pretty viral with it.I read it twice before forming an opinion. My honest take: most of the complaints are skill issues! 🤷♂️Nevertheless, the post is well written and...
AWS FOR THE REAL WORLD ⏱️ Reading time: 10 minutes 🎯 Main Learning: Describe the agent: model, prompt, tools and AWS runs the orchestration loop behind one API call! 📝 Blog Post Hey Reader 👋🏽 If you've ever built an agent on AWS, you know the pain: glue Bedrock, Lambda, and DynamoDB together, grab LangGraph or Strands, then also own the orchestration loop, the memory layer, and your own tracing. 😅 A "simple" agent ends up with multiple layers of pain.AWS just shipped something that takes most...
AWS FOR THE REAL WORLD ⏱️ Reading time: 12 minutes 🎯 Main Learning: Wrapping a multi-account AWS org in multiple layers of guardrails, featuring SCPs, RCPs, CloudTrail and Bugdet Actions 📝 Blog Post Hey Reader 👋🏽As you hopefully know, we're really obsessed with security, observability and auditability. That's why we've carefully crafted our AWS Organization's setup. 🏗️ In this issue, we want to walk you through our most important guardrails! Including all the whats and whys. 😊 Sponsored AWS...